Bulk Data Operations and Remote Access
From Programming Google App Engine, 1st edition, 2010.
This article originally appeared as the chapter "Bulk Data Operations and Remote Access" in Programming Google App Engine, 1st edition, published in 2010.
This chapter was elided from subsequent editions because the tools it described were not officially supported, and the mechanism they use was slow and cumbersome. The tools are still included in the Python SDK and are interesting in their own right. This text is made available in case it is useful, and may be out of date.
Note in particular that the bulk data tools were revised after this was published, and never officially documented. You may need to consult the relevant source files to get the tools to work.
The datastore is designed for retrieving and processing data at a rate suitable for interactive web applications. A single request may need to update a few entities, or query for and retrieve several dozen. Larger amounts of work triggered by interactive actions are not typically expected to be performed within a single web request. (App Engine’s facility for such work, task queues, is discussed in "Task Queues and Scheduled Tasks".) User-initiated actions tend to fit into this model of short requests.
Administrative actions, such as one-off chores performed by the application’s maintainers and staff, sometimes follow a different model. You may need to create or update thousands of entities from a data file, or download the complete contents of the datastore for archival or offline testing. A change to a data model in a new version of the software may require modifying millions of entities to match before the software can be deployed.
You could build features into the application to do these things, and that may be appropriate for routine maintenance tasks. But App Engine has a feature that makes it easy to do ad hoc work with a live application, driven from your own computer: a remote access API.
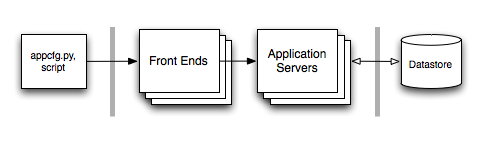
With the remote access API, utilities running on your computer can call the live application’s services, such as the datastore, using the same APIs and libraries that the application uses. Each service call becomes a web request that is processed by a request handler. Each interaction uses a secure connection and is restricted to developer accounts. The following figure shows how the remote API request handler gives transparent access to the live application’s services.
[Figure: Architecture of remote API, with remote calls performed by a web hook]
App Engine includes a tool for uploading and downloading data via the remote API. The tool can create new datastore entities using data from a comma-separated values (CSV) data file (which can be exported and imported from most spreadsheet applications), and can create CSV files with data from the app’s datastore. It can use the app’s data models to validate data before storing it, and can be extended to perform custom transformations on the data. The tool also makes it easy to do a straight download of the entire datastore, and can upload that data back to the app, or to another app.
App Engine also has a tool for running a Python command line session with the remote API. With this remote shell tool, you can execute arbitrary Python statements using the Python API, and service calls will operate on the live application.
These remote access features come in two parts: the remote API request handler, and the tools and libraries that call the handler. The remote API handler is available for both Python and Java applications, and is included with each runtime environment. Both versions of the remote API use the same network protocol, so any tool that works with the Python version also works with the Java version.
Currently, the remote access tools and libraries are only available for Python. You can use these tools and libraries with a Java application via the Java remote API request handler. You will need to download and install the Python SDK to get the tools and libraries. For some features, you may also need to re-implement your data models using the Python data modeling library (described in "Data Modeling with Python"). See "Installing the Python SDK".
In this chapter, we’ll describe how to set up the remote API request handler for Python and Java apps, and how to use the bulk upload and download tools from the Python SDK. We’ll also look at the Python remote shell utility. Finally, we’ll look at how to use the remote API directly in your own Python scripts.
Setting Up the Remote API for Python
The Python remote API request handler is included in the runtime environment. You can set it up at a URL path of your choosing in your login: admin.
Here’s an excerpt at sets up the remote API URL using the path /remote_api:
handlers: - url: /remote_api script: $PYTHON_LIB/google/appengine/ext/remote_api/handler.py login: admin
The $PYTHON_LIB portion of the script path gets replaced by the system with the actual path to the App Engine libraries.
You can test this URL in a browser using the development server. Visit the URL (such as http://localhost:8080/remote_api), and make sure it redirects to a fake authentication form. Check the box to sign in as an administrator, and submit. You should see this message:
This request did not contain a necessary header.
The remote API expects an HTTP header identifying the remote API protocol version to use, which the browser does not provide. But this is sufficient to test that the handler is configured correctly.
Setting Up the Remote API for Java
To use the remote API tools with a Java application, you set up a URL path with a servlet provided by the SDK, namely com.google.apphosting.utils.remoteapi.RemoteApiServlet. You can choose any URL path; you will give this path to the remote API tools in a command-line argument. Be sure to restrict access to the URL path to administrators.
The following excerpt for your deployment descriptor (/remote_api, and restricts it to administrator accounts:
<servlet>
<servlet-name>remoteapi</servlet-name>
<servlet-class>com.google.apphosting.utils.remoteapi.RemoteApiServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>remoteapi</servlet-name>
<url-pattern>/remote_api</url-pattern>
</servlet-mapping>
<security-constraint>
<web-resource-collection>
<web-resource-name>remoteapi</web-resource-name>
<url-pattern>/remote_api</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
</auth-constraint>
</security-constraint>
Using the Bulk Loader Tool
The bulk loader tool is part of the Python SDK, and requires that Python be installed on your computer. The main tool is called bulkloader.py. On Windows, the Python SDK installer puts this command in the command path. On Mac OS X, the Launcher creates a symbolic link to the tool at /usr/local/bin/bulkloader.py when you first run in, which may or may not be in your command path. If you installed the SDK using the Zip archive, the command is in the SDK’s root directory.
You can verify you can run the bulkloader.py command by running it without arguments:
bulkloader.py
If you have a Python application, you can use the appcfg.py upload_data and appcfg.py download_data commands to do data uploads and downloads. These are equivalent to bulkloader.py, but can also derive the application ID and the remote API URL from your appcfg.py; check the App Engine website for the latest.)
If you have a Java application, you just run the bulkloader.py tool, specifying the application ID and remote API URL as command-line arguments:
bulkloader.py --app_id=app-id --url=http://app-id.appspot.com/remote_api ...
You can use the bulk loader tool with the development server by specifying the equivalent remote API URL for it using the --url=... argument. This is useful for testing the remote API URL configuration, for verifying data uploads before doing them with the live application, and for managing test data during development.
You must still specify an accurate --app_id=... argument when using the development server.
bulkloader.py --app_id=app-id \
--url=http://localhost:8080/remote_api ...
The tool will prompt for an email address and password. You can enter any values for these when using the development server.
If you get an “Authentication Failed” error when using the loader with the development server, then your remote API URL is not working. Check your configuration and the development server output.
Installing SQLite
The loader tool keeps track of its progress during an upload or download in a data file, so you can interrupt it and start it again from where it left off instead of starting the job from the beginning. To do this, the tool requires a Python module called sqlite3. You may already have this module installed in your version of Python. Verify that you have the sqlite3 module installed by starting a Python shell and importing it. If nothing happens, the module is installed.
% python Python 2.6.1 (r261:67515, Jul 7 2009, 23:51:51) [GCC 4.2.1 (Apple Inc. build 5646)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import sqlite3 >>>
If you do not have the module, you can get it from the SQLite website. Note that if you compiled your Python installation from source, you will need to recompile it with SQLite support.
If you’d prefer not to install SQLite, you can disable the use of the progress data file in the bulk loader tool by providing this command line argument when running the tool: --db_filename=skip.
Backup and Restore
One of the easiest features of the bulk loader to use is the backup and restore feature. The bulk loader can download every entity of a given kind to a data file, and can upload that data file back to the app to restore those entities. It can also upload the data file to another app, effectively moving all of the entities of a kind from one app to another. You can also use these features to download data from the live app, and “upload” it to the development server for testing (using the --url=... argument mentioned earlier). These features require no additional configuration or code beyond the installation of the remote API handler.
To download every entity of a given kind, run the bulkloader.py tool with the --dump, --kind=... and --filename=... arguments:
bulkloader.py --dump \
--app_id=app-id \
--url=http://app-id.appspot.com/remote_api \
--kind=kind \
--filename=backup.dat
(This is a single command line. The \ characters are line continuation markers, supported by some command shells. You can remove these characters and type all of the arguments on one line.)
To upload a data file created by --dump, thereby recreating every entity in the file, use the --restore argument instead of --dump:
bulkloader.py --restore \
--app_id=app-id \
--url=http://app-id.appspot.com/remote_api \
--kind=kind \
--filename=backup.dat
When using --dump and --restore, entities are not validated using the app’s model classes. They are dumped and restored directly as they appear in the datastore.
Entity keys are preserved, including system-assigned numeric IDs. Properties with key values will remain valid as long as the entities they are referring to are in the app, or are part of the dump being restored. Restoring an entity with the same key as an existing entity will replace the existing entity.
Keys are preserved even if you upload to an app other than the one that originally contained the dumped entities. If you restore an entity with a system-assigned numeric ID, the ID counter for the given key path and kind is advanced past the restored ID, so future new entities will not overwrite the restored entity.
Uploading Data
The bulk loader uploads data from your computer to your application. Out of the box, the loader supports reading data from a data file, and the loader can be customized extensively. This makes it easy to produce a set of fixed information, such as information about products in an online store, and upload it to the app as entities in the datastore. The translation is obvious: each row represents one entity, and each column represents a property of the entity. The tool reads data files in the comma-separated values (CSV) file format, which can be exported by most spreadsheet applications, including Microsoft Excel and Google Spreadsheets.
To perform the translation, the bulk loader needs to know the intended data types and property names for each column. You describe this in a file of Python code that defines a “loader” class for each kind to be imported. The class can define additional code to use to translate each string value from the data file to an appropriate datastore value, and can post-process entities before they are saved to add or delete properties and create additional entities. The loader class can even replace the CSV file reading routine to read data in other formats.
Here is a simple loader definition file, let’s call it
from google.appengine.tools import bulkloader
import datetime
# Import the app's data models directly into
# this namespace. We must add the app
# directory to the path explicitly.
import sys
import os.path
sys.path.append(
os.path.abspath(
os.path.dirname(
os.path.realpath(__file__))))
from models import *
def get_date_from_str(s):
if s:
return datetime.datetime.strptime(s, '%m/%d/%Y').date()
else:
return None
class BookLoader(bulkloader.Loader):
def __init__(self):
bulkloader.Loader.__init__(self, 'Book',
[('title', str),
('author', str),
('copyright_year', int),
('author_birthdate', get_date_from_str),
])
loaders = [BookLoader]
The loader definition file must do several things:
It must import or define a data model class for each kind to import, using the Python data modeling API. The loader file does not have the app directory in the module load path, so the loader file must add it. The modules should be imported directly into the local namespace.
It must define (or import) a loader class for each kind to import, a subclass of the
Loaderclass in the packagegoogle.appengine.tools.bulkloader. This class must have a constructor (an__init__()method) that calls the parent class’s constructor with arguments that describe the CSV file’s columns.It must define a module-global variable named
loaders, whose value is a list of loader classes.
The loader class’s __init__() method calls its parent class’s __init__() method with three arguments: self (the object being initialized), the kind of the entity to create as a string, and a list of tuples. Each tuple represents a column from the CSV file, in order from left to right. The first element of each tuple is the property name to use. The second element is a Python function that takes the CSV file value as a string and returns the desired datastore value in the appropriate Python value type. (Refer to [the property types table] for a list of the Python value types for the datastore.)
For simple data types, you can use the constructor for the type as the type conversion function. In the example above, we use str to leave the value from the CSV file as a string, and int to parse the CSV string value as an integer. Depending on the output of your spreadsheet program, you can use this technique for long, float, db.Text and other types whose constructors accept strings as initial arguments. For instance, users.User takes an email address as a string argument.
The bool type constructor returns False for the empty string, and True in all other cases. If your CSV file contains Boolean values in other forms, you’ll need to write a converter function, like this:
def bool_from_string(s):
return s == 'TRUE'
Dates, times and datetimes usually require a custom converter function to make an appropriate datetime.datetime value from the string. As above, you can use the datetime.datetime.strptime() function to parse the string in a particular format. Tailor this to the output of your spreadsheet program.
To create a multi-valued property, you can use a type conversion function that returns a list value. However, the function must get all of its data from a single cell (though you can work around this by tweaking the file reader routine, described below). It cannot reference other cells in the row, or other rows in the table.
Storing a key value (a reference to another entity) is usually a straightforward matter of defining a type conversion function that uses db.Key.from_path() with the desired kind and a key name derived from a CSV file value.
By default, the bulk loader creates each entity with a key with no ancestors, the given kind, and a system-assigned numeric ID. You can tell the bulk loader to use a custom key name instead of a numeric ID by defining a method of your loader class named generate_key(). This method takes takes as arguments a loop counter (i) and the row’s column values as a list of strings (values), and returns either a string key name, or a db.Key object. The db.Key object can include an entity group parent key. If the function returns None, a system-assigned numeric ID will be used.
class BookLoader(bulkloader.Loader):
# ...
def generate_key(self, i, values):
# Use the first column as the key name.
return values[0]
If an entity is uploaded with the same key as an entity that already exists in the datastore, the new entity will replace the existing entity. You can use this effect to download, modify, then re-upload data to update existing entities instead of creating new ones.
You can “skip” an unused column in the CSV file by giving it a property name that begins with an underscore. The Python data modeling API does not save attributes beginning with an underscore as properties, so the final entity will not have a property with this name. You can re-use the same dummy property name for all columns you wish to skip:
class BookLoader(bulkloader.Loader):
def __init__(self):
bulkloader.Loader.__init__(self, 'Book',
[('_UNUSED', lambda x: None),
('title', str),
('author', str),
('_UNUSED', lambda x: None),
('_UNUSED', lambda x: None),
('copyright_year', int),
# ...
])
If you have a column that is to be the entity key name (via generate_keys()) and you do not want this value to also become a property, you must “skip” the column in the column list using this technique. The bulk loader will complain if it finds more columns than are declared in the list.
The bulk loader uses the Python data modeling API to construct, validate and save entities. If your app is written in Python, you just use the model classes of your app for this purpose, and get the validation for free.
If your app is written in Java, you have a choice to make. You can either implement Python data model classes that resemble your application’s data model, or you can define Python data models that allow arbitrary properties to be set by the loader without validation. For information on defining data models in Python, see "Data Modeling with Python". To define a model class that allows all properties and does no validation, simply define a class like the following for each kind in the loader file, above the definition of the loader classes:
from google.appengine.ext import db
class Book(db.Expando):
pass
The loader class can do post-processing on an entity after it is created but before it is saved to the datastore. This gives you the opportunity to inspect the entity, add or remove properties, and even create additional entities based on each row of the data file. To perform post-processing, implement a method named handle_entity() on the loader class. This takes an instance of the model class as its only argument (entity). It should return the instance to create, a list of model instances if more than one entity should be created, or None if no entity should be created.
You can extend the loader class to read file formats other than CSV files. To do this, you override the generate_records() method. This method takes a filename (filename), and returns a Python generator. Each iteration of the generator should yield a list of strings for each entity to create, where each string corresponds to a property defined in the loader’s constructor. You can use a generate_records() routine to massage the columns processed by the loader so that all the information needed for a single property appears in the column’s value, such as to assemble what will eventually become a multi-valued property from multiple columns in the data file.
You can override the initialize() method of the loader to perform actions at the beginning of an upload. This method takes the input file’s name (filename) and a string given on the command line as the --loader_opts=... argument (loader_opts), which you can use to pass options to this method. Similarly, you can override the finalize() method to do something after the upload is complete.
To start the upload for a Java app or a Python app, run the bulkloader.py command as follows:
bulkloader.py
--app_id=app-id \
--url=http://app-id.appspot.com/remote_api \
--config_file=loaders.py \
--kind=Book \
--filename=bookdata.csv
If you have a Python app, you can use appcfg.py upload_data to do the same thing, with fewer arguments to type. (The app ID and remote API URL are derived from the app’s configuration file.)
appcfg.py upload_data \
--config_file=loaders.py \
--kind=Book \
--filename=bookdata.csv \
app-dir
The --config_file=... argument specifies the file of Python code that defines the loader classes. The --kind=... argument states the kind of the entities to import from the data file; the loader figures out which Loader class and model class to use using the kind. --filename=... is the name of the CSV file.
If your CSV file’s first row is a header row and not actual data, add the --has_header argument to skip the first row.
If any row of the CSV file fails to translate to an entity, either because a type conversion function raised an exception or because the corresponding model class does not consider a converted value valid, the bulk loader stops the upload and reports the error. If you have sqlite3 installed, you can start the upload from where it left off (after fixing the offending value in the CSV file) by running the command again with the same arguments.
You can do a test run of an upload without actually uploading any data by adding the --dry_run argument. This causes the loader to process the CSV file and construct and validate each entity object, and report any errors it finds. It doesn’t upload any data or otherwise access the app.
Downloading Data
You can use the bulk loader to download data from the app’s datastore as well as upload it. The download feature is symmetrical with the upload feature: it supports downloading an app’s entities and adding them as rows to a comma-separated values (CSV) data file. You provide Python code that describes how entities should be saved, and you can customize the download process to perform data transformations or output other file formats.
Similar to the loader class for uploads, the download feature uses a file of Python code that defines an exporter class for each kind of entity to download. The exporter class specifies which property goes in which column of the resulting CSV file, and can include value transformation functions to get the entity data into a format accepted by your spreadsheet program.
Here is a simple exporter definition file that is symmetric with the loader definition example in the previous section. Data downloaded with this exporter can be loaded back in with the loader. Let’s call this file
from google.appengine.tools import bulkloader
import datetime
# Import the app's data models directly into
# this namespace. We must add the app
# directory to the path explicitly.
import sys
import os.path
sys.path.append(
os.path.abspath(
os.path.dirname(
os.path.realpath(__file__))))
from models import *
def make_str_for_date(d):
if d:
return d.strftime('%m/%d/%Y')
else:
return ''
class BookExporter(bulkloader.Exporter):
def __init__(self):
bulkloader.Exporter.__init__(self, 'Book',
[('title', str, None),
('author', str, ''),
('copyright_year', int, ''),
('author_birthdate', make_str_for_date, ''),
])
exporters = [BookExporter]
The exporter definition file must do several things:
It must import or define a data model class for each kind to export, using the Python data modeling API. The exporter file does not have the app directory in the module load path, so the exporter file must add it. The modules should be imported directly into the local namespace.
It must define (or import) an exporter class for each kind to export, a subclass of the
Exporterclass in the packagegoogle.appengine.tools.bulkloader. This class must have a constructor (an__init__()method) that calls the parent class’s constructor with arguments that describe the CSV file’s columns.It must define a module-global variable named
exporters, whose value is a list of exporter classes.
You can safely put your exporter class in the same file as the loader classes, if you like. You can even put them in the same file as your models if that makes sense for your application. You provide the name of the file that defines the exporters using the --filename=... command line argument.
The loader class’s __init__() method calls its parent class’s __init__() method with three arguments: self (the object being initialized), the kind of the entity to create as a string, and a list of tuples. Each tuple represents a column from the CSV file, in order from left to right. The first element of each tuple is the name of a property on each entity. The second element is a Python function that takes the datastore value (as a Python representation of a datastore value type) and returns the string value to add to the CSV file. For the exporter, each tuple also requires a third element that specifies the default value to use if a given entity does not have this property (a string). If the default value is None, then the bulk loader will consider it an error if it finds an entity without this property and abort.
The desired behavior of the type conversion function depends on your spreadsheet application. In most cases, the result of passing the datastore value to the str constructor is sufficient. For Boolean values, you may want a converter function that emits 'TRUE' instead of 'True':
def make_str_for_bool(b):
return 'TRUE' if b else 'FALSE'
For datetime value types (such as datetime.date), you can call the strftime() method of the value in a converter function to produce a string form of the date in the desired format, as in the example above.
If you pass a Key value (such as a reference property) to str, you get an encoded key string. This value contains all of the information about the key, and you can reconstruct the Key object by passing this string to the Key constructor.
The default exporter behavior does not save the key of each entity to the CSV file. You can change the behavior of the exporter by overriding the output_entities() method. This method takes a generator that yields model instances in key order (entity_generator), and does all the work to produce a file. The output filename is accessible using the output_filename member of the exporter (self.output_filename).
You can also override the initialize() method to do work before the download begins. This method takes the name given by --filename=... and the string given by --exporter_opts=..., as the filename and exporter_opts arguments, respectively. There’s also a finalize() method you can override, which is called after the download is complete (with no arguments).
To download data with the bulk loader and exporter classes, run the bulkloader.py command as follows (notice the --download option that wasn’t there in the upload command):
bulkloader.py
--download \
--app_id=app-id \
--url=http://app-id.appspot.com/remote_api \
--config_file=exporters.py \
--kind=Book \
--filename=bookdata.csv
For a Python application, you can also start a download using appcfg.py download_data, like so:
appcfg.py download_data \
--config_file=exporters.py \
--kind=Book \
--filename=bookdata.csv \
app-dir
Controlling the Bulk Loader
You can control the rate that the bulk loader transfers data using command-line arguments:
--num_threads=..., the maximum number of loader threads to spawn. The default is 10.--batch_size=..., the maximum number of entities to create or download with each remote API call. The loader combines puts and gets into batches to reduce the number of remote API calls needed. If you have large entities, set this number low so that the total size of a batch call does not exceed one megabyte. The default is 10.--bandwidth_limit=..., the maximum number of bytes per second to send or receive on average. The default is 250 kilobytes per second.--rps_limit=..., the maximum number of records per second to send or receive on average. The default is 20 records per second.--http_limit=..., the maximum number of HTTP requests to make per second. The default is 15 requests per 2 seconds (7.5 per second).
If you restrict your app’s Google Accounts authentication to a Google Apps domain, the bulk loader needs to know the domain for authentication purposes. You provide this with the --auth_domain=... argument.
The bulk loader uses a temporary database file to keep track of where in a loading job it is in case it is interrupted. Re-running the interrupted tool with the same arguments restarts the job from where it left off. By default, the name of this file is bulkloader-progress-..., where ... is the timestamp of the current run. You can specify a custom name and location for this file with the --db_filename=... argument. If you specify a value of skip for this argument, the bulk loader will not use a file to record progress. (If you do not have sqlite3 installed, you must specify --db_filename=skip.)
The loader also writes a log of its actions to a file named bulkloader-log-... (also with a timestamp in the name). You can change this name with --log_filename=....
For downloads, the loader stashes downloaded entities into a temporary data file named bulkloader-results-.... You can change the name of this file with --result_db_filename=....
Using the Remote Shell Tool
With the remote API handler installed, you can use a tool included with the Python SDK to manipulate a live application’s services from an interactive Python shell. You interact with the shell using Python statements and the Python service APIs. This tool works with both Java and Python applications using the remote API handler.
To start a shell session, run the remote_api_shell.py command. As with the other Python SDK commands, this command may already be in your command path.
remote_api_shell.py app-id
The tool prompts for your developer account email address and password. (Only registered developers for the app can run this tool, or any of the remote API tools.)
By default, the tool connects to the application using the domain name app-id.appspot.com, and assumes the remote API handler is installed with the URL path /remote_api. To use a different URL path, provide the path as an argument after the application ID:
remote_api_shell.py app-id /admin/util/remote_api
To use a different domain name, such as to use a specific application version, or to test the tool with the development server, give the domain name with the -s ... argument:
remote_api_shell.py -s dev.latest.app-id.appspot.com app-id
The shell can use any service API that is supported by the remote API handler. This includes URL Fetch, Memcache, Images, Mail, Google Accounts, and of course the datastore. (As of this writing, XMPP is not supported by the remote API handler.) Several of the API modules are imported by default for easy access.
The tool does not add the current working directory to the module load path by default, nor does it know about your application directory. You may need to adjust the load path (sys.path) to import your app’s classes, such as your data models.
Here is an example of a short shell session:
% remote_api_shell.py clock
Email: juliet@example.com
Password:
App Engine remote_api shell
Python 2.5.1 (r251:54863, Feb 6 2009, 19:02:12)
[GCC 4.0.1 (Apple Inc. build 5465)]
The db, users, urlfetch, and memcache modules are imported.
clock> import os.path
clock> import sys
clock> sys.path.append(os.path.realpath('.'))
clock> import models
clock> books = models.Book.all().fetch(6)
clock> books
[<models.Book object at 0x7a2c30>, <models.Book object at 0x7a2bf0>,
<models.Book object at 0x7a2cd0>, <models.Book object at 0x7a2cb0>,
<models.Book object at 0x7a2d30>, <models.Book object at 0x7a2c90>]
clock> books[0].title
u'The Grapes of Wrath'
clock> from google.appengine.api import mail
clock> mail.send_mail('juliet@example.com', 'test@example.com',
'Test email', 'This is a test message.')
clock>
To exit the shell, press Control-D.
Using the Remote API from a Script
You can call the remote API directly from your own Python scripts using a library from the Python SDK. This configures the Python API to use the remote API handler for your application for all service calls, so you can use the service APIs as you would from a request handler directly in your scripts.
Here’s a simple example script that prompts for a developer account email address and password, then accesses the datastore of a live application.
#!/usr/bin/python
import getpass
import sys
# Add the Python SDK to the package path.
# Adjust these paths accordingly.
sys.path.append('~/google_appengine')
sys.path.append('~/google_appengine/lib/yaml/lib')
from google.appengine.ext.remote_api import remote_api_stub
from google.appengine.ext import db
import models
# Your app ID and remote API URL path go here.
APP_ID = 'app-id'
REMOTE_API_PATH = '/remote_api'
def auth_func():
email_address = raw_input('Email address: ')
password = getpass.getpass('Password: ')
return email_address, password
def initialize_remote_api(app_id=APP_ID,
path=REMOTE_API_PATH):
remote_api_stub.ConfigureRemoteApi(
app_id,
path,
auth_func)
remote_api_stub.MaybeInvokeAuthentication()
def main(args):
initialize_remote_api()
books = models.Book.all().fetch(10)
for book in books:
print book.title
return 0
if __name__ == '__main__':
sys.exit(main(sys.argv[1:]))
The ConfigureRemoteApi() function (yes, it has a TitleCase name) sets up the remote API access. It takes as arguments the application ID, the remote API handler URL path, and a callable that returns a tuple containing the email address and password to use when connecting. In this example, we define a function that prompts for the email address and password, and pass the function to ConfigureRemoteApi().
The function also accepts an optional fourth argument specifying an alternate domain name for the connection. By default, it uses app-id.appspot.com, where app-id is the application ID in the first argument.
The MaybeInvokeAuthentication() function sends an empty request to verify that the email address and password are correct, and raises an exception if they are not. (Without this, the script would wait until the first remote call to verify the authentication.)
Remember that every call to an App Engine library that performs a service call does so over the network via an HTTP request to the application. This is inevitably slower than running within the live application. It also consumes application resources like web requests do, including bandwidth and request counts which are not normally consumed by service calls in the live app.
On the plus side, since your code runs on your local computer, it is not constrained by the App Engine runtime sandbox or the 30-second request deadline. You can run long jobs and interactive applications on your computer without restriction, using any Python modules you like—at the expense of consuming app resources to marshall service calls over HTTP.

